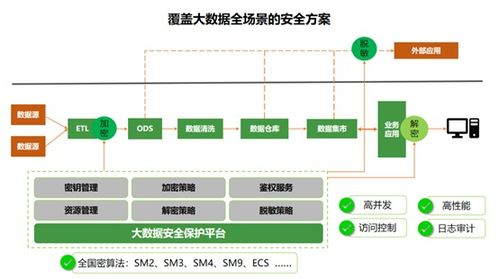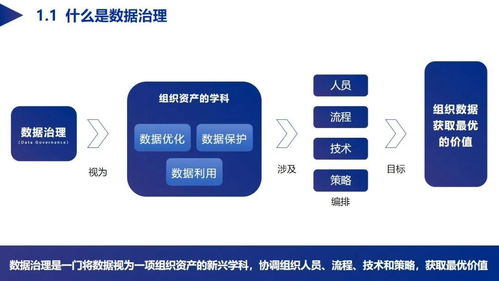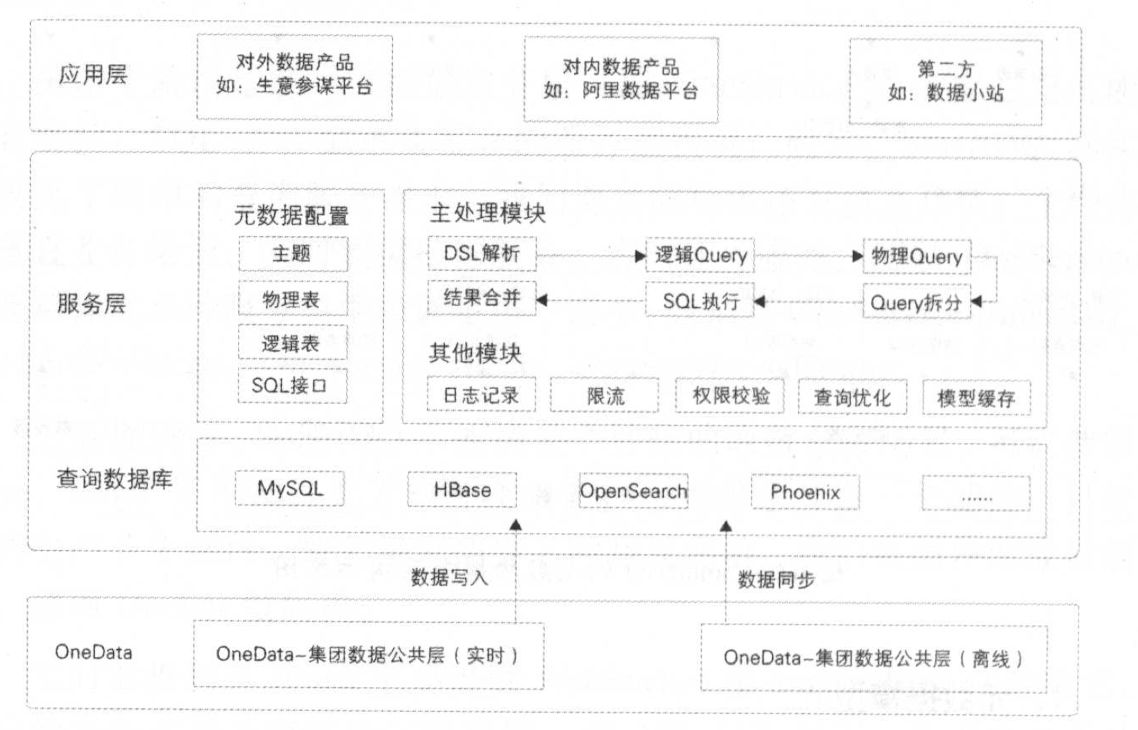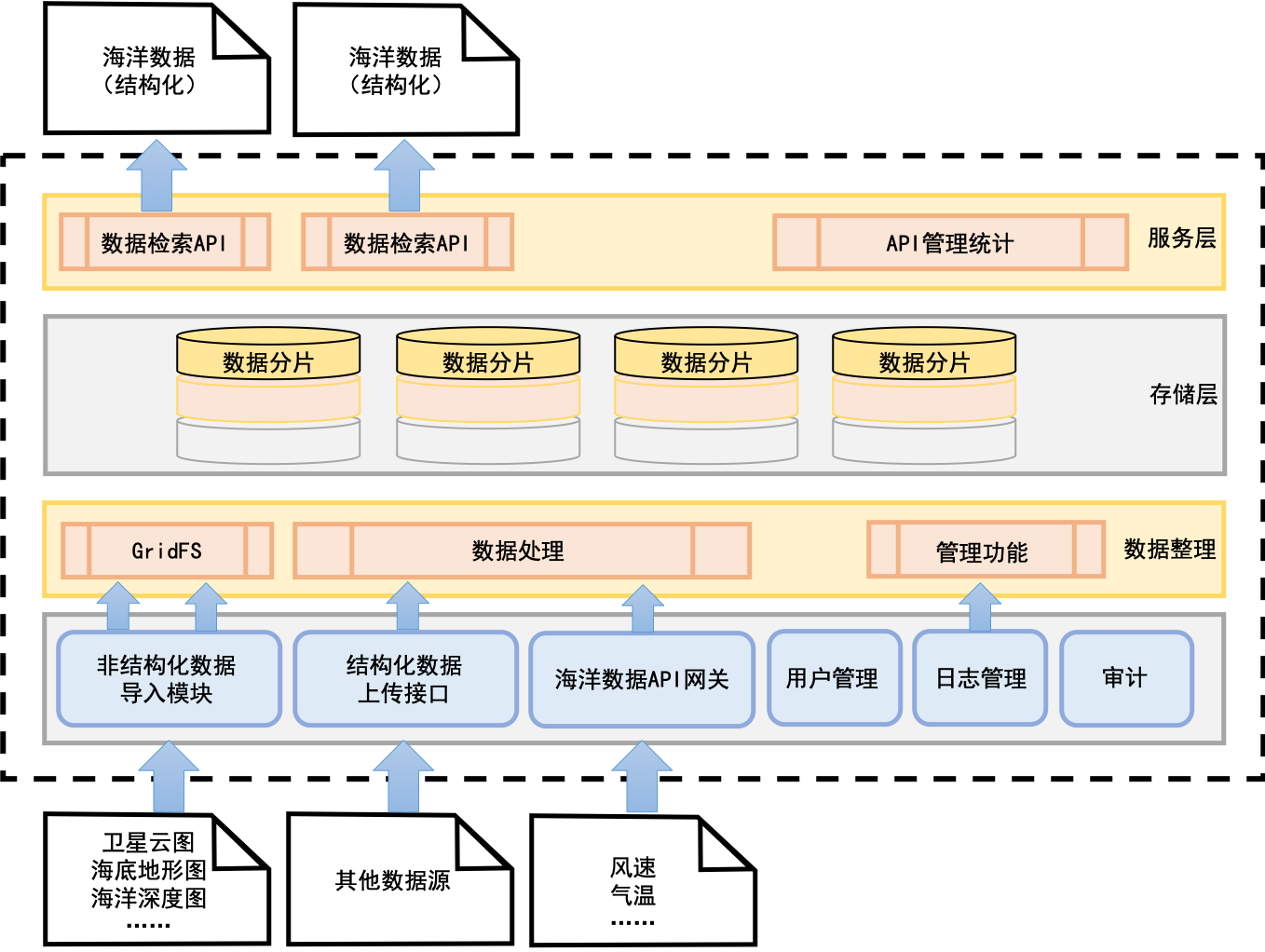
随着企业数据量的激增和业务场景的复杂化,传统集中式存储已难以满足高并发、高可用、跨地域的数据处理需求。基于GridFS的异地分布式存储架构,为构建现代化数据中台和弹性可扩展的数据处理服务提供了强有力的技术支撑。本文旨在探讨如何利用这一架构构建高效、可靠的数据中台体系。
一、 GridFS:分布式文件存储的基石
GridFS是MongoDB用于存储和检索超出16MB文档大小限制文件的一种规范。它将大文件分割成多个块(chunks),并将这些块作为独立的文档存储在集合中,同时将文件的元数据存储在另一个集合中。这种设计使其天然支持分布式存储:
- 分片与负载均衡:文件块可以分布在不同分片(shard)上,实现数据的水平扩展与负载均衡。
- 高可用性:通过副本集(Replica Set)机制,确保每个数据块都有多个副本,即便个别节点故障,数据依然可用。
- 地理位置感知:MongoDB的分片集群可以配置为感知数据中心或区域,将数据块存储在最靠近用户的副本上,从而降低访问延迟。
二、 构建异地分布式存储架构
构建基于GridFS的异地分布式存储,核心在于利用MongoDB分片集群的跨地域部署能力:
- 多数据中心部署:在北京、上海、深圳等业务热点区域部署分片集群的节点(包括配置服务器、分片节点和路由节点)。
- 分片策略配置:
- 基于哈希的分片:将文件块的_id进行哈希,均匀分布到各个分片,适用于无明确地理偏好的海量文件存储。
- 基于范围的分片(结合标签感知):为不同数据中心的分片打上标签(如
zone: 'bj'),并结合文件元数据(如uploadRegion)进行范围分片,确保特定区域生成的文件主要存储在该区域的分片上,实现“数据就近存储”。
- 读写关注与一致性:通过设置适当的读写关注(Read Concern)和写确认(Write Concern),在跨地域场景下平衡数据一致性、可用性和延迟。例如,对于本地读操作,可设置
local读关注以获取最低延迟;对于关键写入,可设置majority写确认以确保数据持久化。
三、 数据中台:统一的数据资产与管理层
基于上述分布式存储,数据中台扮演着“数据资产化与管理中枢”的角色:
- 统一元数据管理:扩展GridFS的元数据集合,纳入业务标签、数据血缘、访问权限、生命周期策略等信息,形成统一的数据资产目录。
- 标准化数据接入与服务:提供统一的API网关和SDK,封装底层存储的复杂性。所有业务系统通过标准接口上传、查询、下载文件,实现数据的“一点接入,全局共享”。
- 数据治理与安全:在接入层实施数据加密(客户端或服务端加密)、访问控制(基于角色的权限管理)与审计日志,确保数据安全合规。结合生命周期管理策略,自动将冷数据归档至成本更低的存储层。
四、 弹性可扩展的数据处理服务
数据处理服务构建于数据中台之上,利用分布式存储的特性实现高效计算:
- 微服务化架构:将图片处理、视频转码、文档解析、大数据分析等处理功能拆分为独立的微服务。每个服务无状态,可独立水平扩展。
- 事件驱动与流处理:当文件通过数据中台API上传后,可自动发布一个包含文件元数据的事件(如到Kafka)。数据处理服务订阅相关事件,触发对应的处理流水线(如上传图片后自动生成缩略图)。
- 就近计算与缓存:结合“数据就近存储”的优势,调度处理任务到文件所在区域的数据中心进行计算,大幅减少数据传输开销。频繁访问的中间或结果数据可存入Redis等分布式缓存,加速后续访问。
- 工作流编排:对于复杂的数据处理任务(如ETL流水线),使用工作流引擎(如Apache Airflow)进行编排,可视化地管理任务依赖、重试与监控。
五、 优势与挑战
核心优势:
无限扩展性:存储与计算能力均可通过增加分片和服务实例线性扩展。
全局低延迟:数据就近存储与计算,优化了用户体验。
高可用与容灾:多副本跨地域分布,具备天然的容灾能力。
技术栈统一:文档数据(元数据)与文件数据使用同一数据库(MongoDB),简化了技术架构。
面临的挑战与考量:
跨地域一致性:需要根据业务容忍度仔细设计一致性模型。
运营成本:多数据中心的基础设施与网络成本较高。
架构复杂性:分片集群的部署、监控与运维需要较高的专业能力。
生态工具:相较于HDFS、对象存储(S3),GridFS在大数据生态(如直接与Spark、Hive集成)中的工具支持相对较少,可能需要额外的适配开发。
基于GridFS构建异地分布式存储,是打造面向海量非结构化数据、具备全局服务能力的数据中台的一种有效实践。它通过将分布式数据库的弹性、扩展性与文件存储需求深度融合,为上层多样化的数据处理服务提供了坚实、灵活的数据底座。成功的关键在于根据具体的业务场景、成本预算和技术实力,审慎设计分片策略、数据一致性模型和微服务架构,并配以完善的监控与运维体系。