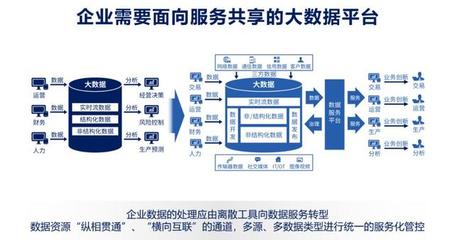
在数字化转型浪潮席卷全球的今天,企业积累了海量的数据资产。许多企业在数据应用的道路上,往往面临着“最后一公里”的困境:数据处理能力强,但数据价值交付难。数据服务化,正成为打通这“最后一公里”的关键路径与核心引擎。
一、何为数据服务化?
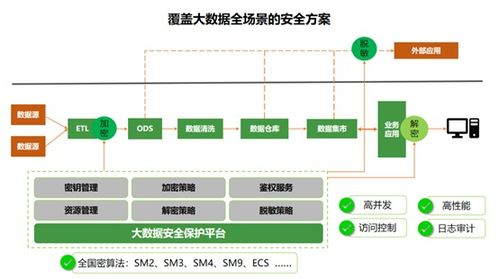
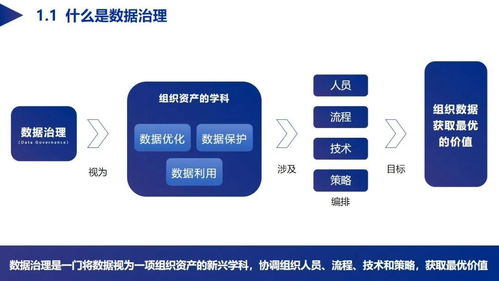
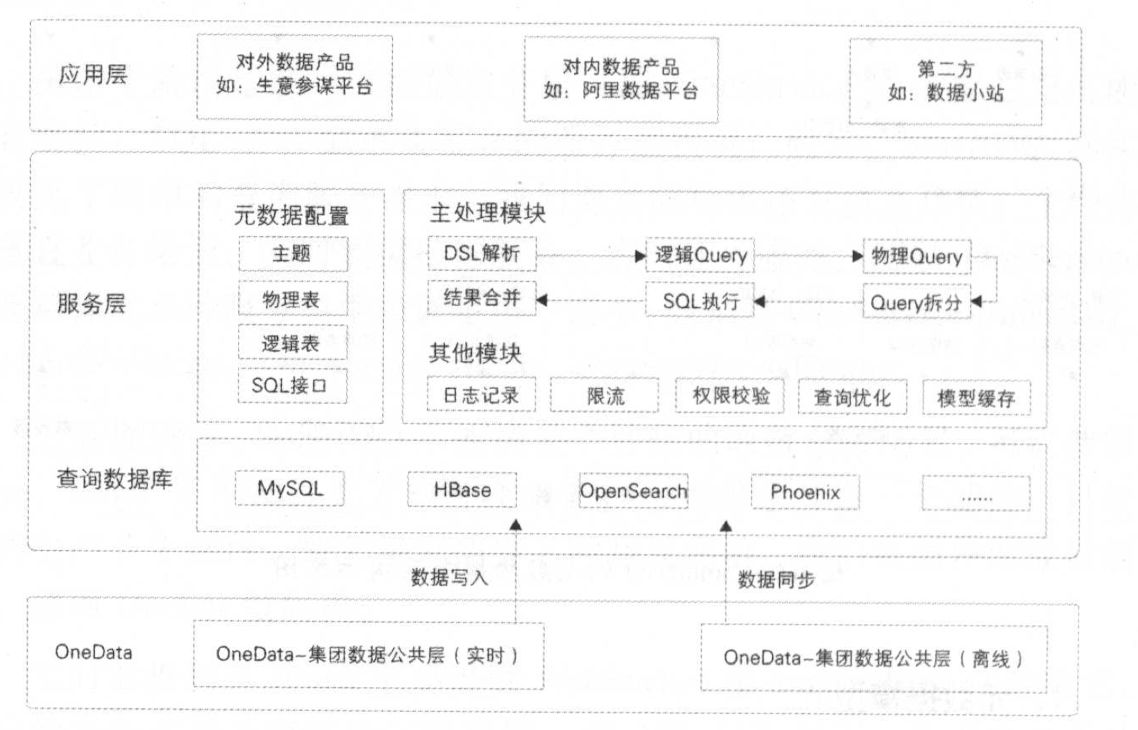
数据服务化并非一个全新的概念,它代表着一种将数据从静态的、孤立的“资源”转变为动态的、可被便捷调用和消费的“服务”的核心理念与实践。传统的数据处理流程,如ETL、数据仓库建设,主要关注数据的整合、清洗与存储,其产出物是报表、指标或数据集。而数据服务化则更进一步,它将这些处理后的数据封装成标准的、可复用的API接口或微服务,使得业务系统、应用程序乃至合作伙伴能够像调用水电煤一样,按需、实时、安全地获取所需的数据能力。
数据处理服务是数据服务化落地的具体承载。它不再仅仅是一个后台的、批处理的任务,而是演变为一套标准化的、可管理的服务体系。这套体系负责将原始数据经过加工、计算、封装,最终以服务的形式对外提供,其核心目标是降低数据消费的技术门槛,提升数据价值的流通效率。
二、为何需要数据服务化?
企业数据应用的“最后一公里”障碍,主要体现在以下几个方面:
- 响应慢,时效差:传统批量报表模式无法满足实时决策、个性化推荐等场景的即时性需求。
- 烟囱林立,复用难:各业务线重复开发数据接口,标准不一,形成新的数据孤岛,造成资源浪费和维护成本高昂。
- 消费门槛高:业务人员或前端应用开发者需要深入理解底层数据模型和技术细节才能使用数据,协作效率低下。
- 安全与管控薄弱:数据直接暴露或通过非标准方式传递,存在泄露风险,且访问权限难以精细化管控。
数据服务化正是针对这些痛点的系统化解决方案。它通过建立统一的数据服务网关,实现数据的“一次加工,多次服务”,确保数据口径一致;通过标准API提供实时或准实时的数据访问,支撑敏捷业务;通过服务鉴权、流量控制、监控审计等手段,构建起坚固的数据安全与运营防线。
三、如何构建数据处理服务?
成功实施数据服务化,构建高效可靠的数据处理服务,需要体系化的建设:
1. 架构层面:微服务与API网关
采用微服务架构思想,将不同的数据处理逻辑(如用户画像查询、实时风控指标计算、商品推荐模型调用)封装成独立的微服务。前端通过统一的API网关进行访问,网关负责路由、认证、限流、监控等通用功能,实现服务治理的统一化。
2. 能力层面:分层与解耦
数据处理服务通常可分为三层:
- 基础数据服务:提供对核心实体(如客户、产品、订单)的原子性查询,确保数据的准确性与一致性。
- 聚合计算服务:基于业务场景,将基础数据进行关联、统计、聚合,提供开箱即用的业务指标(如月度销售额、用户活跃度)。
* 智能决策服务:集成AI/ML模型,提供预测、分类、推荐等高级数据智能能力。
各层服务解耦设计,支持独立开发、部署和扩展。
3. 技术层面:流批一体与云原生
利用Flink、Spark等流批一体处理框架,使同一套逻辑既能处理历史数据,也能处理实时流数据,简化技术栈。拥抱云原生技术(容器化、Kubernetes、服务网格),实现数据处理服务的弹性伸缩、高可用和高效运维。
4. 运营层面:全生命周期管理
建立数据服务的目录市场,让服务可被发现、理解和申请。实施从服务设计、开发、测试、部署、上线、监控到下线归档的全生命周期管理。持续监控服务性能(如响应时间、可用性)和使用情况(如调用量、热门服务),并据此进行优化和迭代。
四、价值与未来展望
数据服务化将为企业带来显著的商业价值:
- 加速创新:业务团队能快速获取数据能力,试验新想法,缩短产品上市周期。
- 降本增效:消除重复开发,提升数据团队产能,让数据工程师更专注于高价值的数据加工与模型构建。
- 提升体验:支撑更实时、更个性化的客户交互与内部决策,直接提升用户满意度和运营效率。
- 释放价值:让数据在安全可控的前提下,在企业内部甚至生态伙伴间顺畅流动,最大化数据资产价值。
数据服务化将与DataOps、AIOps等理念深度融合,向更加自动化、智能化的方向发展。数据处理服务将不仅仅是数据的“搬运工”和“计算器”,更将成为企业智能业务系统的“中枢神经”,动态协调数据、算法与业务需求,持续驱动企业跨越数据应用的“最后一公里”,驶入数字化转型的快车道。