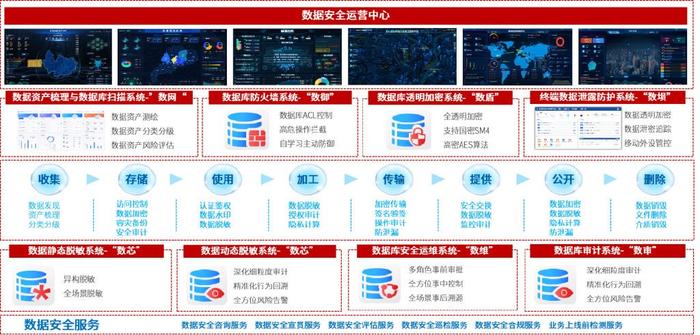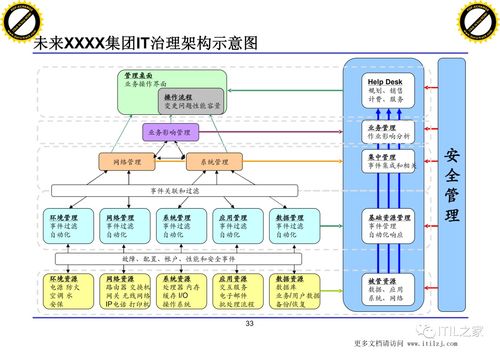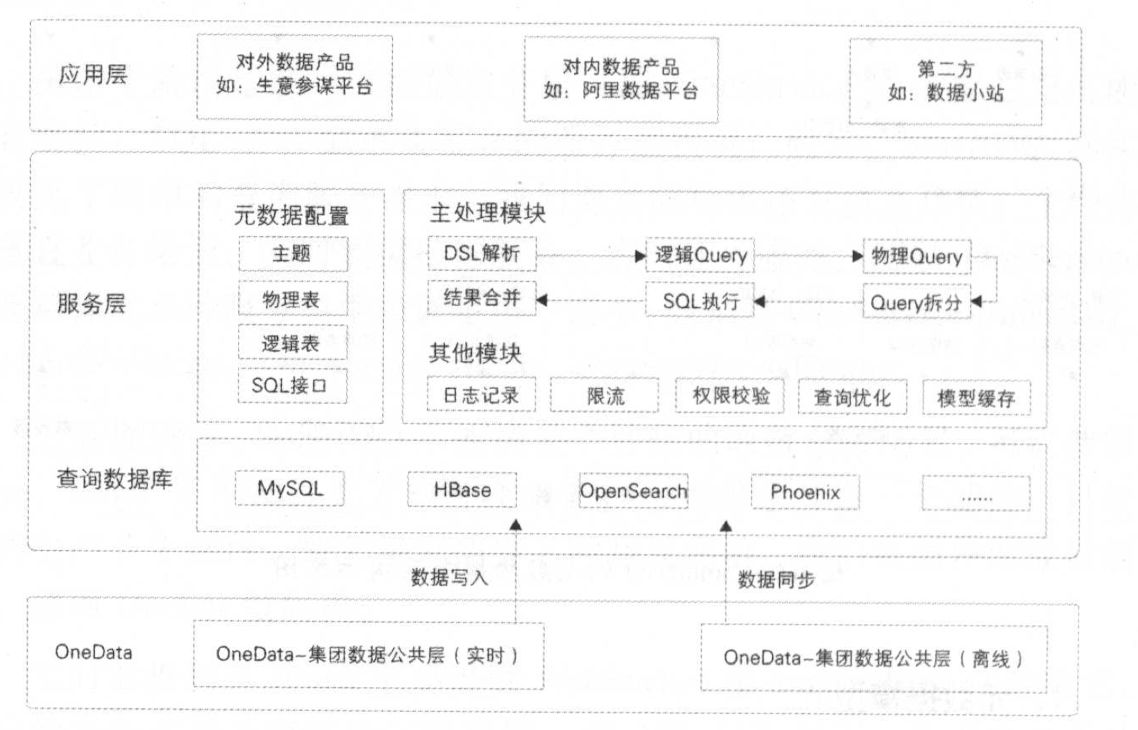
《大数据之路》的“数据服务”与“数据处理服务”章节,深刻阐述了在大数据体系中,如何将原始、庞杂的数据资源,转化为稳定、可靠、易用的数据能力,并最终服务于业务与决策。这不仅关乎技术实现,更是一种将数据从“资产”状态推向“价值”状态的核心方法论。
一、 数据服务:数据价值的交付终点
数据服务被定位为数据价值输出的统一出口。其核心目标是解决“数据在哪里”和“数据怎么用”的问题,旨在降低数据使用门槛,提升数据消费效率。
- 核心理念:从“人找数据”到“数据找人/服务找人”。通过构建标准化的服务接口(API),将数据封装成可被各类应用系统(如报表、产品、运营工具)直接调用的服务,实现数据的“开箱即用”。
- 核心架构与组件:
- 统一服务网关:作为所有数据服务的唯一入口,负责路由、鉴权、限流、监控和计量,保障服务的稳定性与安全性。
- 服务发布与管理:提供标准的服务注册、发布、上下线流程,并具备版本管理能力。
- 多模式服务支持:通常包括:
- 在线查询服务:满足低延迟、高并发的实时或准实时数据查询需求,如用户画像实时查询。
- 离线文件服务:为批量数据同步或数据导出场景提供文件级的数据分发。
- 实时消息推送服务:基于数据变更,主动向订阅方推送消息,适用于监控报警、事件驱动型业务。
- 关键挑战与设计原则:
- 稳定性与性能:作为直接面向业务的组件,必须具备高可用、低延迟、弹性扩缩容的能力。
- 数据一致性:确保服务返回的数据与数据源(如数据仓库)的一致性,尤其在复杂的数据同步链路中。
- 成本与效率:通过查询优化、缓存策略(如多级缓存)、请求合并等技术,在保障体验的同时控制计算与存储成本。
二、 数据处理服务:数据体系的运转引擎
数据处理服务是支撑数据服务乃至整个数据仓库的底层计算能力。它负责执行从原始数据到可服务数据的各种转换、加工与计算任务。
- 定位与范畴:它不是一个单一工具,而是一个由调度系统、计算引擎、质量监控等组成的平台化体系。其输入是各类数据源,输出是结构清晰、质量可信的中间表、明细表、汇总表及模型数据。
- 核心能力分层:
- 任务调度与编排:核心是工作流调度引擎,它负责任务(Job)的依赖解析、定时触发、优先级调度、失败重试与报警。优秀的调度系统能清晰刻画数据生产DAG(有向无环图),确保数据处理有序、高效。
- 异构计算引擎支持:根据处理场景灵活调用不同的计算引擎,如:
- 批处理引擎(如Hive/Spark):用于海量历史数据的ETL(抽取、转换、加载)和T+1的离线计算。
- 流处理引擎(如Flink/Storm):用于实时数据流的处理,满足实时监控、实时特征计算等场景。
- 交互式查询引擎(如Presto/ClickHouse):提供亚秒级到秒级的快速即席查询能力。
- 数据质量保障:将数据质量校验规则(如唯一性、非空、值域、波动率)嵌入处理流程,实现“质量卡点”,问题数据可阻断、可报警、可追溯。
- 元数据与血缘管理:自动采集任务运行中产生的元数据和数据血缘关系。这是理解数据来龙去脉、进行影响分析和故障排查的基石。
- 演进趋势:
- SQL化与平民化:降低数据处理开发门槛,让分析师和业务人员也能通过SQL参与数据加工。
- 流批一体:统一流处理和批处理的计算模型与API,简化开发运维,并支持更灵活的数据处理模式。
- 智能化运维:基于历史运行数据,实现任务智能调优、资源自动弹性分配、异常自动检测与根因分析。
三、 相辅相成:从处理到服务的闭环
数据处理服务与数据服务构成了数据生产消费链条的“供给侧”与“消费侧”。
- 数据处理服务是“幕后英雄”,它确保数据被正确、高效、高质量地生产出来,是数据体系的基石和成本中心。
- 数据服务是“前台窗口”,它负责以最友好的方式将数据能力交付出去,是数据价值的放大器与价值实现的直接触手。
二者通过统一的数据模型和标准化的数据存储层(如数据仓库的维度模型、分层表)紧密衔接。一个健壮的数据处理服务为数据服务提供了可信的数据源;而数据服务反馈的业务使用情况和性能要求,又能反向驱动数据处理流程的优化与新模型的开发。
而言,构建优秀的数据服务与数据处理服务体系,是企业大数据建设从“有数据”走向“用好数据”的必经之路。它要求我们不仅要有强大的技术平台作为支撑,更要有产品化的思维,将数据能力当作一种服务来设计、运营和迭代,最终让数据如水如电般,顺畅地流动并滋养业务的每一个角落。