在《知网大数据治理工具系统详解(上篇)》中,我们介绍了该系统在数据集成、数据标准与数据质量方面的核心能力。本篇将聚焦于该系统的另一大核心模块——数据处理服务,深入剖析其如何将原始、杂乱的数据转化为高质量、高价值的可用资产。
一、 数据处理服务的定位与目标
数据处理服务是知网大数据治理工具系统承上启下的关键环节。它位于数据采集与集成之后,数据分析与应用之前。其主要目标在于:
- 数据精炼化:对集成后的原始数据进行清洗、转换、整合,消除数据噪声和不一致性。
- 结构规范化:将多源异构数据转化为统一、规范的数据模型,便于后续的存储、管理与分析。
- 价值显性化:通过数据加工、衍生计算等,挖掘数据深层信息,生成满足特定业务需求的衍生指标和数据集。
- 服务化输出:将处理后的标准、可信数据,以API、数据服务、数据产品等形式,高效、安全地供给上层应用系统。
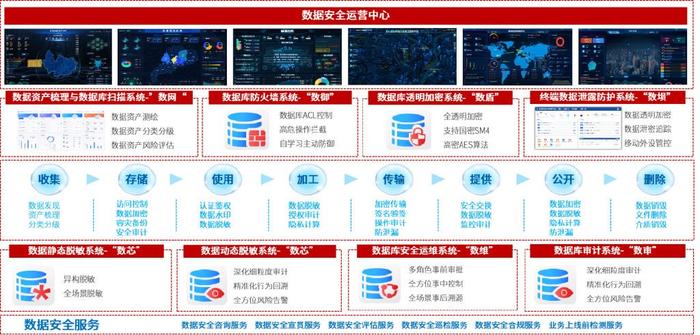
二、 核心功能模块详解
知网数据处理服务模块通常包含以下核心组件:
1. 数据清洗与转换
这是数据处理的基础。系统提供图形化、配置化的数据清洗规则库和转换引擎。
- 清洗功能:支持去重、缺失值处理(填充、剔除)、异常值检测与修正、格式标准化(如日期、单位统一)等。
- 转换功能:支持字段拆分/合并、编码转换(如一码通)、数据脱敏/加密、简单计算(如求和、平均值)等。所有操作均可通过拖拽和参数配置完成,降低技术门槛。
2. 数据融合与关联
针对知网特有的学术资源数据(如期刊论文、学位论文、会议论文、专利、标准等)以及外部接入数据,提供强大的关联融合能力。
- 实体识别与链接:自动识别不同数据源中的同一实体(如学者、机构、主题),并建立唯一标识和关联关系,构建完整的知识实体画像。
- 多维度整合:支持基于主题、时间、作者、机构、参考文献等多个维度进行数据关联与聚合,形成深度整合的数据立方体。
3. 数据加工与衍生计算
基于清洗后的基础数据,通过预置或自定义的计算模型,生成高价值的衍生数据。
- 指标加工:例如,计算学术影响力指标(如篇均被引频次)、合作强度指数、学科交叉度等。
- 特征工程:为学术评价、趋势预测、人才发现等分析场景,构建特征数据集。
- 知识抽取:利用自然语言处理技术,从非结构化文本中抽取关键术语、研究方法、结论等结构化知识。
4. 任务调度与监控
提供可视化的任务编排与调度引擎,确保数据处理流程的自动化、稳定运行。
- 工作流设计:支持将清洗、转换、融合、计算等多个处理步骤编排成一个完整的数据处理流水线。
- 调度执行:支持定时、事件触发、手动等多种触发方式,并能处理任务间的依赖关系。
- 全链路监控:实时监控数据处理任务的运行状态、耗时、数据流量,提供详细的日志和错误告警,便于运维与问题排查。
5. 数据服务与API管理
将处理后的“数据成品”进行服务化封装,实现安全、高效的数据供给。
- 数据服务发布:可将特定的数据集、查询结果或计算指标发布为标准的RESTful API或数据服务接口。
- 服务管理与治理:提供API的权限控制、流量限制、访问审计、版本管理等功能,保障数据服务的安全与稳定。
- 多格式输出:支持以JSON、XML、CSV等多种格式输出数据,满足不同应用系统的需求。
三、 技术特点与优势
- 可视化、低代码操作:大部分数据处理任务可通过配置完成,无需编写复杂代码,提升业务人员参与度。
- 高性能与可扩展性:底层通常采用分布式计算框架(如Spark、Flink),能够处理海量学术数据,并可通过横向扩展应对增长的数据量。
- 内置学术领域模型:预置了针对学术文献、科研人员、科研机构等实体的数据处理规则和关联模型,开箱即用。
- 全流程可追溯:提供数据血缘追踪功能,能清晰展示数据的来源、处理过程及下游应用,保障数据可信度与合规性。
- 与知网生态深度集成:能够无缝对接知网知识资源总库、学术评价平台等,形成数据治理到知识服务的闭环。
四、 典型应用场景
- 构建机构知识库:帮助高校、科研机构整合内部科研成果数据,并进行清洗、规范、关联,构建高质量的本机构知识资产体系。
- 支撑学科分析与评价:为学科评估提供经过深度处理的、指标统一的底层数据,支持更精准的趋势分析、对标分析和影响力评价。
- 赋能智慧图书馆服务:处理并关联读者的借阅数据、检索行为数据与文献资源数据,为个性化推荐、学科服务提供数据支撑。
- 打造科研管理平台:为科研管理部门的项目、成果、人才管理提供统一、准确的数据来源,提升管理决策的科学性。
###
数据处理服务作为知网大数据治理工具系统的“加工厂”,将原始数据原料转化为可直接用于分析、决策和创新的高价值数据产品。它不仅是技术工具,更是连接数据资源与业务价值的桥梁。通过其高效、智能的数据处理能力,知网大数据治理工具系统最终助力各类机构盘活数据资产,释放数据潜能,驱动学术研究与管理服务的数字化转型与智能化升级。
(全文完)